Abstract
Given an input video of a person and a new garment, SwiftTry can synthesize a new video where the person is wearing the specified garment while maintaining spatiotemporal consistency. We reconceptualize video virtual try-on as a conditional video inpainting task, with garments serving as input conditions. Specifically, our approach enhances image diffusion models by incorporating temporal attention layers to improve temporal coherence. To reduce computational overhead, we propose ShiftCaching, a novel technique that maintains temporal consistency while minimizing redundant computations. Furthermore, we introduce the TikTokDress dataset, a new video try-on dataset featuring more complex backgrounds, challenging movements, and higher resolution compared to existing public datasets.
Our Pipeline
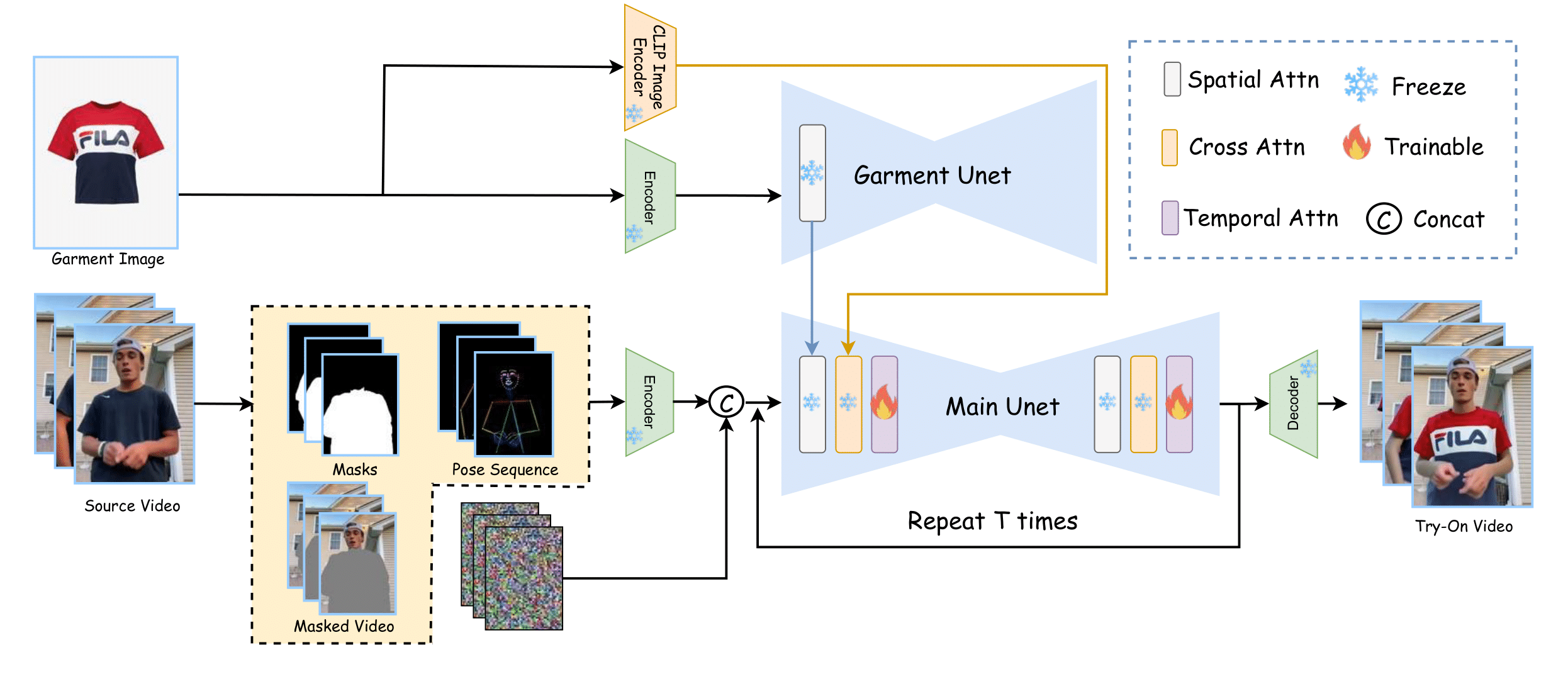
Given a source video and a garment image, our method first extracts the masked video, corresponding masks, and pose sequence (in yellow box). The masked video is encoded into the latent space by the VAE Encoder, which is then concatenated with noise, masks, and pose features before being processed by the Main U-Net. To inpaint the garment during the denoising process, we use a Garment U-Net and a CLIP encoder to extract both low- and high-level garment features. Finally, the VAE decoder decodes the latents into a try-on video clip. The training has 2 stages:
- Stage 1: We pre-train the Main U-net, Garment U-net and Pose Encoder on image virtual try-on datasets.
- Stage 2: We inflate the Unet, inserting temporal layers and then finetune on video try-on dataset.
Proposed ShiftCaching
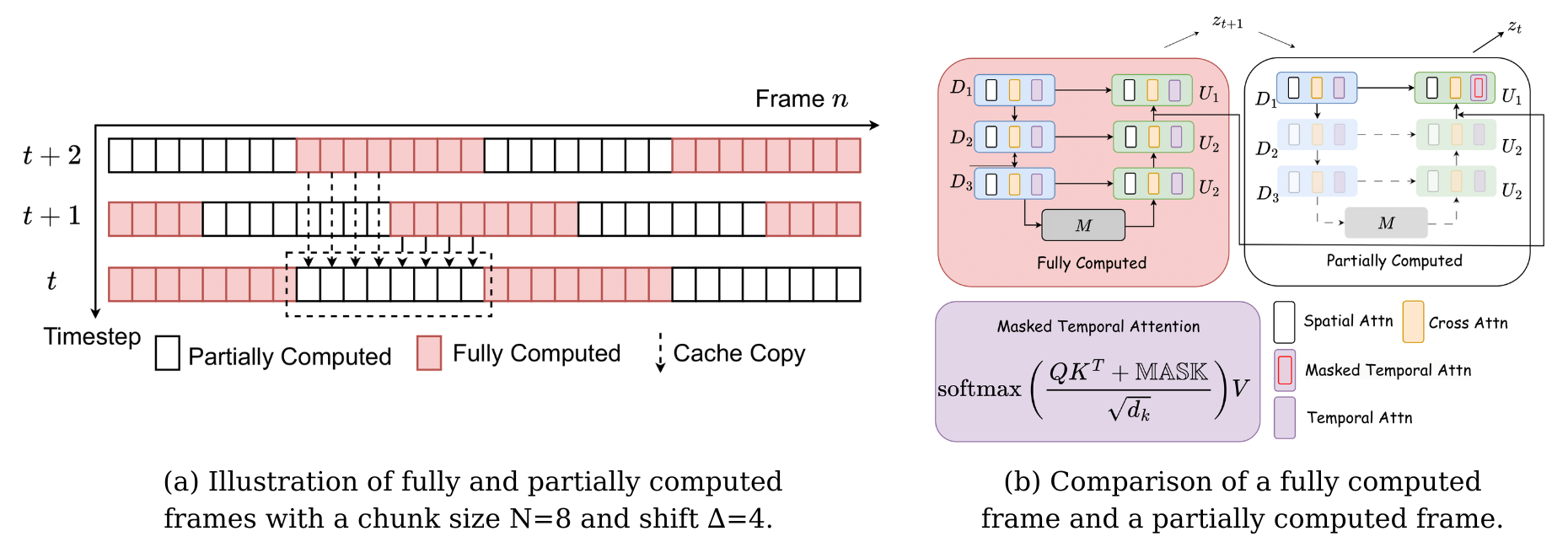
To further achieve good temporal coherence and smoothness without recomputing the overlapped regions, we propose a shifting mechanism during inference.
(a) The long video is divided into non-overlapping chunks (\(S=0\), \(N=8\)). At each DDIM sampling timestep \(t\), we shift these chunks by a predefined value \(\Delta=4\) between two consecutive frames, allowing the model to process different compositions of noisy chunks at each step. To further accelerate the inference process, we can skip a random chunk to reduce redundant computation during denoising. However, naively dropping chunks without adjustment can lead to abrupt changes in noise levels in the final results.(b) Following DeepCache, which notes that adjacent denoising steps share significant similarities in high-level features, we instead perform partial computations on the Main U-Net. Specifically, we use a cache to copy the latest features from the fully computed timestep \(z_{t+1}\) (red) and use these features to partially compute the current latent \(z_t\) (white), bypassing the deeper blocks of the U-Net.
Try-on Results
Our results on TikTokDress dataset
Our results on VVT dataset
BibTeX
@article{hung2025SwiftTry,
author = {Hung Nguyen*, Quang Qui-Vinh Nguyen*, Khoi Nguyen, Rang Nguyen},
title = {SwiftTry: Fast and Consistent Video Virtual Try-On with Diffusion Models},
journal = {AAAI},
year = {2025},
}